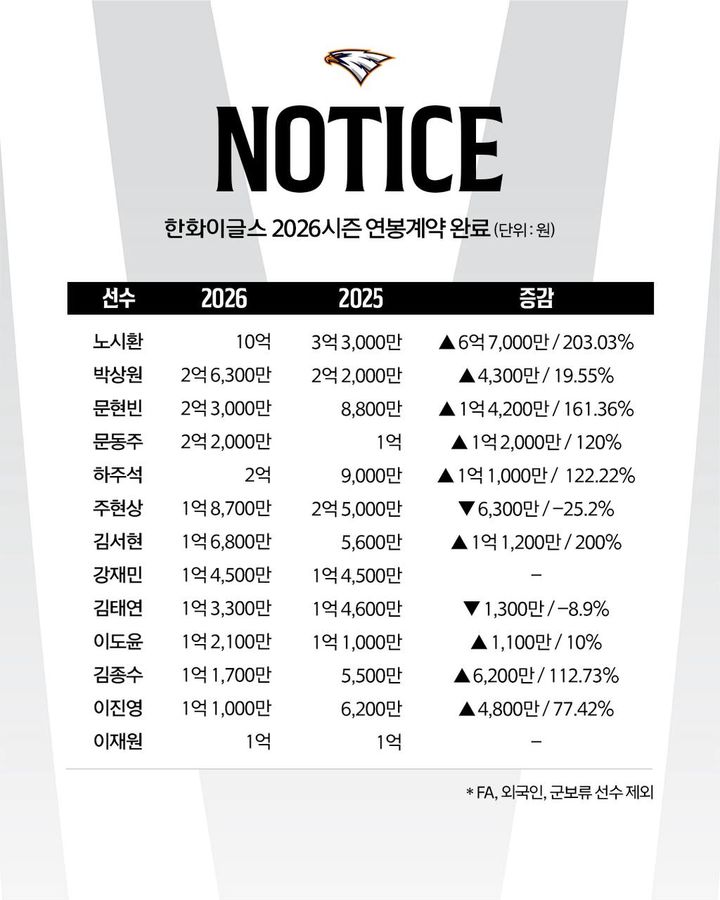
ETRI, 강소형 국산 생성 언어모델 '이글' 공개
등록 2024.11.28 13:52:12
3B급 추가학습 쉬운 한국어 소형 언어모델
국어 데이터 비중 매우 높아…중소·중견기업 지원 기대
연산 횟수 줄고 효율적인 학습·추론 가능
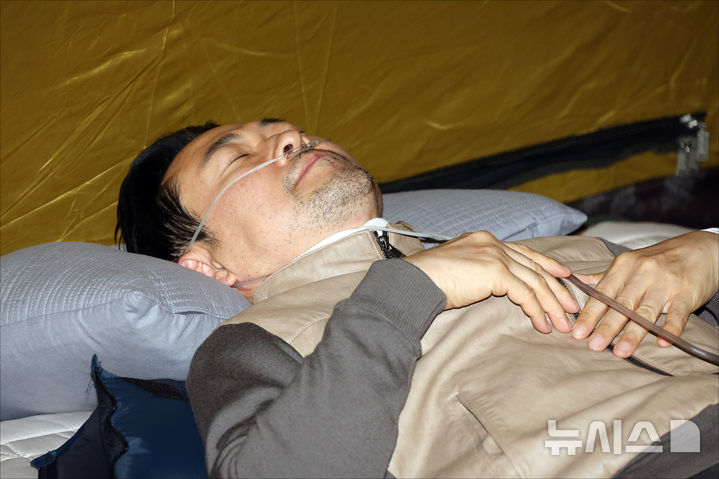
![[대전=뉴시스] ETRI 연구진이 이글을 활용해 스스로 계획과 식을 만들어 제시된 수학문제를 해결하는 개념 증명용 데모 시스템에 대해 이야기를 나누고 있다.(사진=ETRI 제공) *재판매 및 DB 금지](https://img1.newsis.com/2024/11/28/NISI20241128_0001715319_web.jpg?rnd=20241128132910)
[대전=뉴시스] ETRI 연구진이 이글을 활용해 스스로 계획과 식을 만들어 제시된 수학문제를 해결하는 개념 증명용 데모 시스템에 대해 이야기를 나누고 있다.(사진=ETRI 제공) *재판매 및 DB 금지
[대전=뉴시스] 김양수 기자 = 국내 연구진이 국어 중심의 신경망 기반 소형 생성 언어모델을 개발해 일반에 공개했다.
한국전자통신연구원(ETRI)은 한국어 기반 30억개 파라미터(3B)급 신경망 기반 소형 생성 언어모델(SLM) '이글(Eagle)'을 개발해 오픈소스인 허깅페이스 허브(HuggingFace Hub)에 공개했다고 28일 밝혔다.
생성형 언어모델은 방대한 텍스트(글) 데이터로부터 인간의 언어능력을 학습해 사용자의 질문이나 지시에 따라 자연스러운 대화나 다양한 텍스트 콘텐츠를 만들어내는 시스템이다.
30억개 파라미터(3B)급은 신경망 모델이 학습과정에서 조정할 수 있는 수치화된 값들이 30억 개 존재한다는 의미로, 파라미터의 수가 많을수록 모델의 복잡성이 커지고 일반적으로 더 뛰어난 학습능력을 보유한다.
생성형 언어모델 분야의 글로벌 빅테크 기업들은 100억~1000억 개 파라미터 이상의 중대형 모델을 공개했으며 최근에는 10억~40억 개 파라미터 규모의 소형 개방형 모델을 공개하고 있다.
하지만 이런 모델은 한국어 어휘를 음절이나 바이트 단위로 처리하기 때문에 동일한 문장을 표현하는 데 많은 연산이 필요하다.
또 학습된 데이터 중 한국어 데이터가 전체의 5%에도 미치지 못해 한국어 이해 및 생성능력이 영어 등 주요 언어에 비해 상대적으로 낮았다.
이번에 ETRI 연구진이 개발한 언어모델은 한국어 데이터 비중이 매우 높아 연산횟수를 줄이면서도 효율적인 학습과 추론이 가능하다.
이에 앞서 ETRI가 지난 4월 공개한 13억 파라미터 모델은 한국어로 주어진 숫자 연산을 수행하는 미세조정 실험에서 글로벌 기업 모델의 절반 수준(50%)의 규모에도 특정 작업들에서 약 15% 더 높은 성능을 기록했다.
특히 국내 기업들이 공개한 기존 한국어 중심 모델은 질의응답 과업에 적합하게 조정된 기정렬 모델이라는 한계가 있었으나 ETRI서 공개한 모델은 미세조정이 적용되지 않은 기초모델로 제공됐다.
기초모델은 기정렬된 모델에 비해 새로운 목적의 과업에 추가학습을 적용할 경우 응용모델의 기대성능이 더 높다. 학습시간도 약 20% 내외로 단축돼 더 우수한 성능을 발휘한다는 장점도 있다.
이 모델은 생성형 AI 응용 개발과정에서 연산비용 부담을 느끼는 중소·중견 기업에 적합하고 기초모델에 특화된 용도를 반영해 추가학습을 수행, 기업별 맞춤형 기초모델을 제작할 수 있는 연장학습에도 용이하다.
향후 ETRI는 더 많은 지식을 내포하는 70억 개 파라미터 규모의 모델과 사전정렬을 통해 추가학습 없이 사용자의 요청에 맞게 응답을 수행할 수 있는 모델도 확보해 순차적으로 공개할 예정이다.
ETRI 권오욱 언어지능연구실장은 "현재 공개된 언어모델들은 풍부한 자원을 기반으로 하지 못해 해외 우수 모델들보다 나을 수는 없다"면서도 "하지만 상대적으로 작은 한국어 토종모델이 필요한 산학연 여러 분야의 연구개발에는 큰 도움이 될 것"이라고 말했다.
◎공감언론 뉴시스 [email protected]
Copyright © NEWSIS.COM, 무단 전재 및 재배포 금지